 Build a Custom Plugin
Build a Custom Plugin
Browse Kestra's integrations and learn how to create your own plugins.
The purpose of plugins
Plugins are the building blocks of Kestra's tasks and triggers. They encompass components interacting with external systems and performing the actual work in your flows.
Kestra comes prepackaged with hundreds of plugins, and you can also develop your own custom plugins.
To integrate with your internal systems and processes, you can build custom plugins. If you think it could be useful to others, consider contributing your plugin to our open-source community.
Setup for Plugin Development
Plugin Template
To get started with building a new plugin, make sure to use the plugin-template, as it comes prepackaged with the standardized repository structure and deployment workflows.
That template will create a project hosting a group of plugins — we usually create multiple subplugins for a given service. For example, there's only one plugin for AWS, but it includes many subplugins for specific AWS services.
Note that the Kestra plugin library version must align with your Kestra instance. You may encounter validation issues during flow creation (e.g. Invalid bean response with status 422) when some plugins are on an older version of the Kestra plugin library. In that case, you may want to update the file plugin-yourplugin/gradle.properties and set the version property to the correct Kestra version e.g.:
version=0.17.0-SNAPSHOT
kestraVersion=[0.17,)
It's not mandatory that your plugin version matches the Kestra version, Kestra's official plugins version will always match the minor version of Kestra but it's only a best practice.
Then rebuild and publish the plugin.
Requirements
Kestra plugins development requirements are:
- Java 21 or later.
- IntelliJ IDEA (or any other Java IDE, we provide only help for IntelliJ IDEA).
- Gradle (included most of the time with the IDE).
Create a new plugin
Here are the steps:
- Go on the plugin-template repository.
- Click on Use this template.
- Choose the GitHub account you want to link and the repository name for the new plugin.
- Clone the new repository:
git clone git@github.com:{{user}}/{{name}}.git. - Open the cloned directory in IntelliJ IDEA.
- Enable annotations processors.
- If you are using an IntelliJ IDEA < 2020.03, install the lombok plugins (if not, it's included by default).
Once you completed the steps above, you should see a similar directory structure:
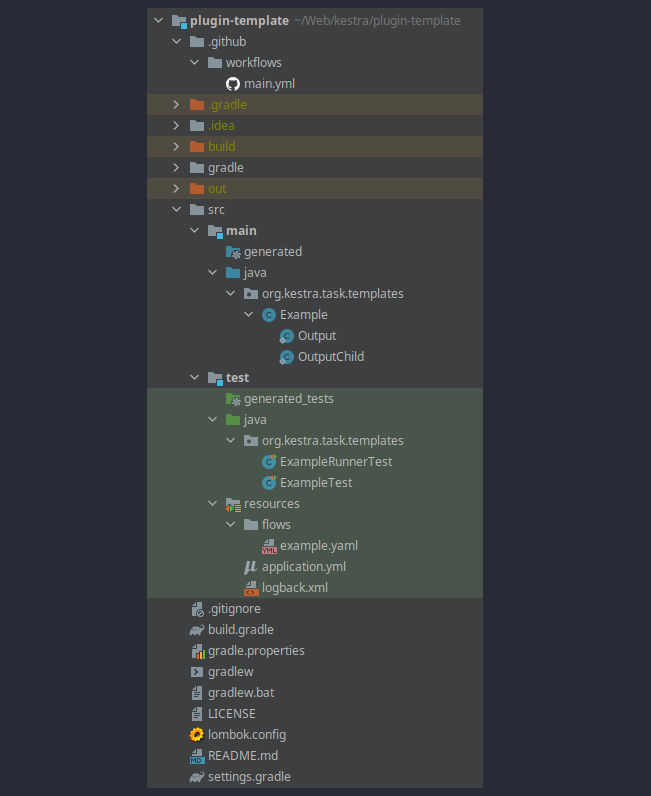
As you can see, there is one generated plugin: the Example class representing the Example plugin (a task).
A project typically hosts multiple plugins. We call a project a group of plugins, and you can have multiple sub-groups inside a project by splitting plugins into different packages. Each package that has a plugin class is a sub-group of plugins.
Plugin icons
Plugin icons need to be added in the SVG format — see an example here in the JIRA plugin.
Where can you find icons?
- for proprietary systems, Wikipedia is a good source of SVG icons
- for AWS services, the AWS icons is a great resource
- Google Fonts Icons
- Feather Icons.
Gradle Configuration
We use Gradle as a build tool. This page will help you configure Gradle for your plugin.
Mandatory configuration
The first thing you need to configure is the plugin name and the class package.
- Change in
settings.gradletherootProject.name = 'plugin-template'with your plugin name. - Change the class package: by default, the template provides a package
io.kestra.plugin.templates, just rename the folder insrc/main/java&src/test/java - Change the package name on
build.gradle: replacegroup "io.kestra.plugin.templates"to the package name.
Now you can start developing your task or look at other optional gradle configuration.
Other configurations
Include some dependencies on plugins
You can add as many dependencies to your plugins, they will be isolated in the Kestra runtime. Thanks to this isolation, we ensure that two different versions of the same library will not clash and have runtime errors about missing methods.
The build.gradle handle most of Kestra use case by default using compileOnly group: "io.kestra", name: "core", version: kestraVersion for Kestra libs.
But if your plugin need some dependencies, you can add as many as you want that will be isolated, you just need to add api dependencies:
api group: 'com.google.code.gson', name: 'gson', version: '2.8.6'
Develop a Task
Here are the instructions to develop a new task.
Runnable Task
Lets look at this one more deeply:
Class annotations
@SuperBuilder
@ToString
@EqualsAndHashCode
@Getter
@NoArgsConstructor
These are required in order to make your plugin work with Kestra. These are Lombok annotations that allow Kestra and its internal serialization to work properly.
Class declaration
public class ReverseString extends Task implements RunnableTask<ReverseString.Output>
ReverseStringis the name of your task, and it can be used on Kestra withtype: io.kestra.plugin.templates.ReverseString(aka:{{package}}.{{className}}).- Class must extend
Taskto be usable. implements RunnableTask<ReverseString.Output>: must implementRunnableTaskto be discovered and must declare the output of the taskReverseString.Output.
Properties
@PluginProperty(dynamic = true)
private String format;
Declare all the properties that you can pass to the current task in a flow. For example, this will be a valid yaml for this task:
type: io.kestra.plugin.templates.ReverseString
format: "{{ outputs.previousTask.name }}"
You can declare as many properties as you want. All of these will be filled by Kestra executors.
You can use any serializable by Jackson for your properties (ex: Double, boolean, ...). You can create any class as long as the class is Serializable.
Properties validation
Properties can be validated using javax.validation.constraints.* annotations. When the user creates a flow, your task properties will be validated before insertion and prevent wrong definition to be inserted.
The default available annotations are:
@Positive@AssertFalse@AssertTrue@Max@Min@Negative@NegativeOrZero@Positive@PositiveOrZero@NotBlank@NotNull@Null@NotEmpty@Past@PastOrPresent@Future@FutureOrPresent
You can also create your own custom validation. You must defined the annotation as follows:
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = { })
public @interface CronExpression {
String message() default "invalid cron expression ({validatedValue})";
}
And you must also define a factory to inject the validation method:
@Factory
public class ValidationFactory {
private static final CronParser CRON_PARSER = new CronParser(CronDefinitionBuilder.instanceDefinitionFor(CronType.UNIX));
@Singleton
ConstraintValidator<CronExpression, CharSequence> cronExpressionValidator() {
return (value, annotationMetadata, context) -> {
if (value == null) {
return true;
}
try {
Cron parse = CRON_PARSER.parse(value.toString());
parse.validate();
} catch (IllegalArgumentException e) {
return false;
}
return true;
};
}
}
Run
@Override
public ReverseString.Output run(RunContext runContext) throws Exception {
Logger logger = runContext.logger();
String render = runContext.render(format);
logger.debug(render);
return Output.builder()
.reverse(StringUtils.reverse(render))
.build();
}
The run method is where the main logic of your task will do all the work needed. You can use any Java code here with any required libraries as long as you have declared them in the Gradle configuration.
Log
Logger logger = runContext.logger();
To have a logger, you need to use this instruction. This will provide a logger for the current execution and will log appropriately. Do not create your own custom logger in order to track logs on the UI.
Render variables
String render = runContext.render(format);
In order to use dynamic expressions, you need to render them i.e. transform the properties with Pebble. Do not forget to render variables if you need to pass an output from previous variables.
You also need to add the annotation @PluginProperty(dynamic = true) in order to explain in the documentation that you can pass some dynamic variables.
Provide a @PluginProperty annotation even if you didn't set any of its attributes for all variables or the generated documentation will not be accurate.
Kestra storage
You can read any files from Kestra storage using the method runContext.uriToInputStream()
final URI from = new URI(runContext.render(this.from));
final InputStream inputStream = runContext.uriToInputStream(from);
You will get an InputStream in order to read the file from Kestra storage (coming from inputs or task outputs).
You can also write files to Kestra's internal storage using runContext.putTempFile(File file). The local file will be deleted, so you must use a temporary file.
File tempFile = File.createTempFile("concat_", "");
runContext.putTempFile(tempFile)
Do not forget to provide Outputs with the link generated by putTempFile in order for it to be usable by other tasks.
Outputs
public class ReverseString extends Task implements RunnableTask<ReverseString.Output> {
@Override
public ReverseString.Output run(RunContext runContext) throws Exception {
return Output.builder()
.reverse(StringUtils.reverse(render))
.build();
}
@Builder
@Getter
public static class Output implements io.kestra.core.models.tasks.Output {
@Schema(
title = "The reversed string"
)
private final String reverse;
}
}
Each task must return a class instance with output values that can be used in the next tasks.
You must return a class that implements io.kestra.core.models.tasks.Output.
You can add as many properties as you want, just keep in mind that outputs need to be serializable. At execution time, outputs can be accessed by downstream tasks by leveraging outputs expressions e.g. {{ outputs.task_id.output_attribute }}.
If your task doesn't provide any outputs (mostly never), you use io.kestra.core.models.tasks.VoidOutput:
public class NoOutput extends Task implements FlowableTask<VoidOutput> {
@Override
public VoidOutput run(RunContext runContext) throws Exception {
return null;
}
}
Exception
In the run method, you can throw any Exception that will be caught by Kestra and will fail the execution.
We advise you to throw any Exception that can break your task as soon as possible.
Metrics
You can expose metrics to add observability to your task. Metrics will be recorded with the execution and can be accessed via the UI or as Prometheus metrics.
There are two kinds of metrics available:
Counter:Counter.of("your.counter", count, tags);with argsString name: The name of the metricDouble|Long|Integer|Float count: the associated counterString... tags: a list of tags associated with your metric
Timer:Timer.of("your.duration", duration, tags);String name: The name of the metricDuration duration: the recorded durationString... tags: a list of tags associated with your metric
To save metrics with the execution, you need to use runContext.metric(metric).
Name
Must be lowercase separated by dots.
Tags
Must be pairs of tag key and value. An example of two valid tags (zone and location) is:
Counter.of("your.counter", count, "zone", "EU", "location", "France");
Documentation
Remember to document your tasks. For this, we provide a set of annotations explained in the Document each plugin section.
Flowable Task
Flowable tasks are the most complex tasks to develop, and will usually be available from the Kestra core. You will rarely need to create a flowable task by yourself.
When developing such tasks, you must make it fault-tolerant as an exception thrown by a flowable task can endanger the Kestra instance and lead to inconsistencies in the flow execution.
Keep in mind that a flowable task will be evaluated very frequently inside the Executor and must have low CPU usage; no I/O should be done by this kind of task.
In the future, complete documentation will be available here. In the meantime, you can find all the actual Flowable tasks here to have some inspiration for Sequential or Parallel tasks development.
Develop a Trigger
Here is how you can develop a Trigger.
You need to extend PollingTriggerInterface and implement the Optional<Execution> evaluate(ConditionContext conditionContext, TriggerContext context) method.
You can have any properties you want, like for any task (validation, documentation, ...), and everything works the same way.
The evaluate method will receive these arguments:
ConditionContext conditionContext: a ConditionContext which includes various properties such as the RunContext in order to render your properties.TriggerContext context: to have the context of this call (flow, execution, trigger, date, ...).
In this method, you add any logic you want: connect to a database, connect to remote file systems, ... You don't have to take care of resources, Kestra will run this method in its own thread.
This method must return an Optional<Execution> with:
Optional.empty(): if the condition is not validated.Optional.of(execution): with the execution created if the condition is validated.
You have to provide a Output for any output needed (result of query, result of file system listing, ...) that will be available for the flow tasks within the {{ trigger.* }} variables.
Take care that the trigger must free the resource for the next evaluation. For each interval, this method will be called and if the conditions are met, an execution will be created.
To avoid this, move the file or remove the record from the database; take an action to avoid an infinite triggering.
Documentation
Remember to document your triggers. For this, we provide a set of annotations explained in the Document each plugin section.
Develop a Condition
Here is how you can develop a new Condition.
You just need to extend Condition and implement the boolean test(ConditionContext conditionContext) method.
You can have any properties you want like for any task (validation, documentation, ...), everything works the same way.
The test will receive a ConditionContext that will expose:
conditionContext.getFlow(): the current flow.conditionContext.getExecution(): the current execution that can be null for Triggers.conditionContext.getRunContext(): a RunContext in order to render your properties.
This method must simply return a boolean in order to validate the condition.
Documentation
Remember to document your conditions. For this, we provide a set of annotations explained in the Document each plugin section.
Add Unit Tests
To avoid regression, we recommend adding unit tests for all your tasks.
There are two main ways to unit-test your tasks. Both will be regular Micronaut tests, and hence must be annotated with @MicronautTest.
Unit test a RunnableTask
This is the most common way to test a RunnableTask. You create your RunnableTask, and test output or Exception. This will cover most of the cases.
This is same as any Java unit tests, feel free to use any dependencies, test methods, start docker containers, ...
Unit test with a full flow
In case you want to add some unit test with a full flow (In some rare case, it can be necessary; for example, for FlowableTask), here is how you can write the unit test with the full flow.
With this, you will:
- Inject all dependencies with
@Inject. - On
init(), load all the flow on thesrc/resources/flowdirectory. - Run a full execution with
Execution execution = runnerUtils.runOne(null, "io.kestra.templates", "example");. The first parameter is for thetenantIdwhich can be null on tests.
With this execution, you can look at all the properties you want to control (status, taskRunList number, outputs, ...)
To make it work, you need to have an application.yml file with this minimum configuration:
kestra:
repository:
type: memory
queue:
type: memory
storage:
type: local
local:
base-path: /tmp/unittest
And these dependencies on your build.gradle:
testImplementation group: "io.kestra", name: "core", version: kestraVersion
testImplementation group: "io.kestra", name: "repository-memory", version: kestraVersion
testImplementation group: "io.kestra", name: "runner-memory", version: kestraVersion
testImplementation group: "io.kestra", name: "storage-local", version: kestraVersion
This will enable the in memory runner and will run your flow without any other dependencies (kafka, ...).
Document Your Plugin
Here is how you can document your plugin.
First, let us remember the organization of a plugin project:
- The Gradle project can contain several plugins, we call it a group of plugins.
- The package in which a plugin is written in is called a sub-group of plugins. Sometimes, there is only one sub-group, in which case the group and the sub-group are the same.
- Each class is a plugin that provides one task, trigger, condition, etc.
The plugin documentation will be used on the Kestra website and the Kestra UI.
We provide a way to document each level of a plugin project.
Document the plugin group
Manifest attributes
Kestra uses custom manifest attributes to provide top-level group documentation.
The following manifest attributes are used to document the group of plugins:
X-Kestra-Title: by default, the Gradleproject.nameproperty is used.X-Kestra-Group: by default, the Gradlegroup.idproperty with an additional group name is used.X-Kestra-Description: by default, the Gradleproject.descriptionproperty is used.X-Kestra-Version: by default, the Gradleproject.versionproperty is used.
If you follow the plugin structure of the template on GitHub, you should have something like this:
As you can see, the most important documentation attribute is the description, which should be a short sentence describing the plugins.
Additional markdown files
You can add additional markdown files in the src/main/resources/doc directory.
If there is a file src/main/resources/doc/<plugin-group>.md, it will be inlined inside the main documentation page as the long description for the group of plugins.
For example, for the GCP group of plugins, the file is src/main/resources/doc/io.kestra.plugin.gcp.md, and it contains authentication information that applies to all tasks.
If there are files inside the src/main/resources/doc/guides directory, we will list them in a Guides section on the documentation for the group of plugins.
Group Icon
It is possible to provide an icon representing the whole plugin group. If there is a SVG file src/main/resources/icons/plugin-icon.svg, it will be used as the group icon.
Document the plugin sub-groups
Each sub-group can be documented via the io.kestra.core.models.annotations.PluginSubGroup annotation that must be defined at the package level in a package-info.java file.
The @PluginSubGroup annotation allows setting:
- The sub-group
title. If not set, the name of the sub-group will be used. - The sub-group
description, which is a short sentence introducing the sub-group. - The sub-group
categories, which is a list ofPluginCategory. If not set, the categoryMISCwill be used.
For example, for the GCP BigQuery sub-group:
@PluginSubGroup(
title = "BigQuery",
description = "This sub-group of plugins contains tasks for accessing Google Cloud BigQuery.\n" +
"BigQuery is a completely serverless and cost-effective enterprise data warehouse.",
categories = { PluginSubGroup.PluginCategory.DATABASE, PluginSubGroup.PluginCategory.CLOUD }
)
package io.kestra.plugin.gcp.bigquery;
import io.kestra.core.models.annotations.PluginSubGroup;
Sub-Group Icon
Each plugin sub-group can define an icon representing plugins contained in the sub-group. If there is a SVG file src/main/resources/icons/<plugin-sub-group>.svg, it will be used as the icon for the corresponding plugins.
For example, for the GCP BigQuery sub-group, the src/main/resources/icons/io.kestra.plugin.gcp.bigquery.svg file is used.
Document each plugin
Plugin documentation will generate a JSON Schema that will be used to validate flows. It also generates documentation for both the UI and the website (see the kestra plugins doc command).
Document the plugin class
Each plugin class must be documented via the following:
- The
io.kestra.core.models.annotations.Pluginannotation allows providing examples. - The
io.swagger.v3.oas.annotations.media.Schemaannotation, which thetitleattribute will use as the plugin description.
For example, the Query task of the PostgreSQL group of plugins is documented as follows:
@Schema(
title = "Query a PostgresSQL server"
)
@Plugin(
examples = {
@Example(
full = true,
title = "Execute a query",
code = {
"tasks:",
"- id: update",
" type: io.kestra.plugin.jdbc.postgresql.Query",
" url: jdbc:postgresql://127.0.0.1:56982/",
" username: postgres",
" password: pg_passwd",
" sql: select concert_id, available, a, b, c, d, play_time, library_record, floatn_test, double_test, real_test, numeric_test, date_type, time_type, timez_type, timestamp_type, timestampz_type, interval_type, pay_by_quarter, schedule, json_type, blob_type from pgsql_types",
" fetch: true"}
)
}
)
For convenience, the code attribute of the @Example annotation is a list of strings. Each string will be a line of the example. That avoids concatenating multi-line strings in a single attribute.
You can add multiple examples if needed.
Document the plugin properties
In a plugin, all properties must be annotated by io.kestra.core.models.annotations.PluginProperty and should provide documentation via the io.swagger.v3.oas.annotations.media.Schema annotation and validation rules via javax.validation.constraints.*.
The @PluginProperty annotation contains two attributes:
dynamic: set it to true if the property will be rendered dynamically.additionalProperties: you can use it to denote the sub-type of the property. For example, when using aMap<String, Message>, you can set it toMessage.class.
The Swagger @Schema annotation contains a lot of attributes that can be used to document the plugin properties. The most useful are:
title: a short description of a property.description: long description of a property.anyOf: a list of allowed sub-types of a property. Use it when the property type is an interface, an abstract class, or a class inside a hierarchy of classes to denote possible sub-types. This should be set when the property type isObject.
The @Schema and @PluginProperty annotations can be used on fields, methods, or classes.
Many tasks can take input from multiple sources on the same property. They usually have a single from property, a string representing a file in the Kestra Storage, a single object, or a list of objects. To document such property, you can use anyOf this way:
@PluginProperty(dynamic = true)
@NotNull
@Schema(
title = "The source of the published data.",
description = "Can be an internal storage URI, a list of Pub/Sub messages, or a single Pub/Sub message.",
anyOf = {String.class, Message[].class, Message.class}
)
private Object from;
Due to limitations on how JSON Schema works, you cannot add @Schema on a Java enum type and the plugin property that uses this type. We advise avoiding using @Schema on enumerations.
Document the plugin outputs
Outputs should be documented with the io.swagger.v3.oas.annotations.media.Schema annotation in the same way as plugin properties. Please read the section above for more information.
Only use the annotation mentioned above. Never use @PluginProperty on an output.
Document the plugin metrics
Tasks can expose metrics; to document those you must add a @Metric annotation instance for each metric in the @Plugin annotation instance of the task.
For example, to document two metrics: a length metric of type counter and a duration metric of type timer, you can use the following:
@Plugin(
metrics = {
@Metric(name = "length", type = Counter.TYPE),
@Metric(name = "duration", type = Timer.TYPE)
}
)
Build and Publish a Plugin
Use the included Gradle task to build the plugin. Then, you can publish it to Maven Central.
Build a plugin
To build your plugin, execute the ./gradlew shadowJar command from the plugin directory.
The resulting JAR file will be generated in the build/libs directory.
To use this plugin in your Kestra instance, add this JAR to the Kestra plugins path.
Use a custom docker image with your plugin
Adding this Dockerfile to the root of your plugin project:
FROM kestra/kestra:develop
COPY build/libs/* /app/plugins/
You can build and run the image with the following command assuming you're in the root directory of your plugin:
./gradlew shadowJar && docker build -t kestra-custom . && docker run --rm -p 8080:8080 kestra-custom server local
You can now navigate to http://localhost:8080 and start using your custom plugin. Feel free to adapt the Dockerfile to your needs (eg. if you plan to use multiple custom plugins, include all builds directory in it).
Publish a plugin
Here is how you can publish your plugin to Maven Central.
GitHub Actions
The plugin template includes a GitHub Actions workflow to test and publish your plugin. You can extend it by adding any additional testing or deployment steps.
Publish to Maven Central
The template includes a Gradle task that will publish the plugin to Maven Central. You need a Maven Central account in order to publish your plugin.
You only need to configure the gradle.properties to have all required properties:
sonatypeUsername=
sonatypePassword=
signing.keyId=
signing.password=
signing.secretKeyRingFile=
There is a pre-configured GitHub Actions workflow in the .github/workflows/main.yml file that you can customize to your need:
Was this page helpful?